
基于 Ceph 存储的私有云盘
任务背景
NAS(Network Attached Storage) 是一种基于 Linux 操作系统构建的网络附属存储系统,它通过网络提供文件共享服务,实现多个设备之间的数据访问与共享。它通常将一台运行 Linux 的服务器变成一个 文件服务器,可供局域网中的电脑、手机、电视等设备访问。
用户通过 Samba(SMB)、NFS、FTP 等协议访问 NAS 中共享的文件夹,无需插 U 盘、硬盘,任何设备只要连上网就能访问里面的文件、照片、视频等。
虽然使用了NAS存储, 但是对于爆炸式的数据增长仍然感觉力不从心。对于大数据与云计算等技术的成熟, 存储也需要跟上步伐,所以这次我们选用对象存储。
任务要求
1、搭建ceph集群
2、实现对象存储的应用
3、实现nextcloud私有云盘
任务拆解
1、了解ceph
2、搭建ceph集群
3、了解rados原生数据存取
4、实现ceph文件存储
5、实现ceph块存储
6、实现ceph对象存储
7、实现nextcloud私有云盘
学习目标
能够成功部署ceph集群
能够使用ceph共享文件存储,块存储与对象存储
能够说出对象存储的特点
能够基于nextcloud打造私有云盘
一、认识Ceph
Ceph是一个能提供的文件存储、块存储、对象存储的分布式存储系统。它提供了一个可无限伸缩的Ceph存储集群
文件存储、块存储、对象存储
块存储
• 通常对应的是一个裸设备,比如一块磁盘,我们需要格式化后进行挂载才能使用
• lvm、cinder
文件存储
• 文件系统只是数据组织存放的接口,文件系统通常是构建在一个块存储级别以上
• 文件系统被氛围元数据区域和数据区域,对于用户而言,它呈现为一个树形结构,实际上提供的是一个目录
• nfs、glusterfs
对象存储
• 对象存储并没有像文件存储那样划分为元数据区域和数据区域,而是按照不同的对象进行存储
• fastdfs、swift
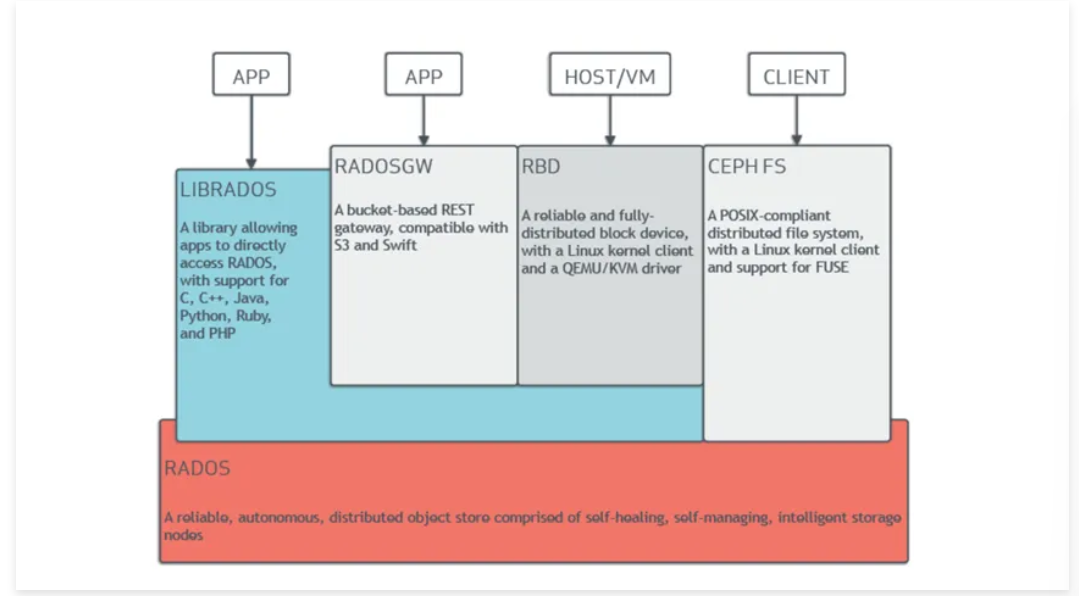
二、Ceph架构
参考官档: https://docs.ceph.com/docs/master/
RADOS: Ceph的高可靠,高可拓展,高性能,高自动化都是由这一层来提供的, 用户数据的存储最终也都是通过这一层来进行存储的
可以说RADOS就是ceph底层原生的数据引擎, 但实际应用时却不直接使用它,而是分为如下4种方式来使用:
• LIBRADOS是一个库, 它允许应用程序通过访问该库来与RADOS系统进行交互,支持多种编程语言。如Python,C,C++等. 简单来说,就是给开发人员使用的接口
• CEPH FS通过Linux内核客户端和FUSE来提供文件系统。(文件存储)
• RBD通过Linux内核客户端和QEMU/KVM驱动来提供一个分布式的块设备。(块存储)
• RADOSGW是一套基于当前流行的RESTFUL协议的网关,并且兼容S3和Swift。 (对象存储)
拓展名词
RESTFUL: RESTFUL是一种架构风格,提供了一组设计原则和约束条件,http就属于这种风格的典型应用。REST最大的几个特点为:资源、统一接口、URI和无状态。
• 资源: 网络上一个具体的信息: 一个文件,一张图片,一段视频都算是一种资源
• 统一接口: 数据的元操作,即CRUD(create, read, update和delete)操作,分别对应于HTTP方法
○ GET(SELECT):从服务器取出资源(一项或多项)
○ POST(CREATE):在服务器新建一个资源
○ PUT(UPDATE):在服务器更新资源(客户端提供完整资源数据)
○ PATCH(UPDATE):在服务器更新资源(客户端提供需要修改的资源数据)
○ DELETE(DELETE):从服务器删除资源
• URI(统一资源定位符): 每个URI都对应一个特定的资源。要获取这个资源,访问它的URI就可以。最典型的URI即URL
• 无状态: 一个资源的定位与其它资源无关,不受其它资源的影响
S3 (Simple Storage Service 简单存储服务): 可以把S3看作是一个超大的硬盘, 里面存放数据资源(文件,图片,视频等),这些资源统称为对象。这些对象存放在存储段里,在S3叫做bucket
和硬盘做类比, 存储段(bucket)就相当于目录,对象就相当于文件
硬盘路径类似 /root/file1.txt
S3的URI类似 s3://bucket_name/object_name
三、Ceph集群
集群组件
Ceph集群包括Ceph OSD、Ceph Monitor两种守护进程
Ceph OSD(Object Storage Device): 功能是存储数据,处理数据的复制、恢复、回填、再均衡,并通过检查其他OSD守护进程的心跳来向Ceph Monitors提供一些监控信息
Ceph Monitor: 是一个监视器,监视Ceph集群状态和维护集群中的各种关系
Ceph存储集群至少需要一个Ceph Monitor和两个 OSD 守护进程
Monitor守护进程推荐为奇数个,建议3个及以上。因为Ceph底层判断OSD节点故障,需要过半原则
集群环境准备
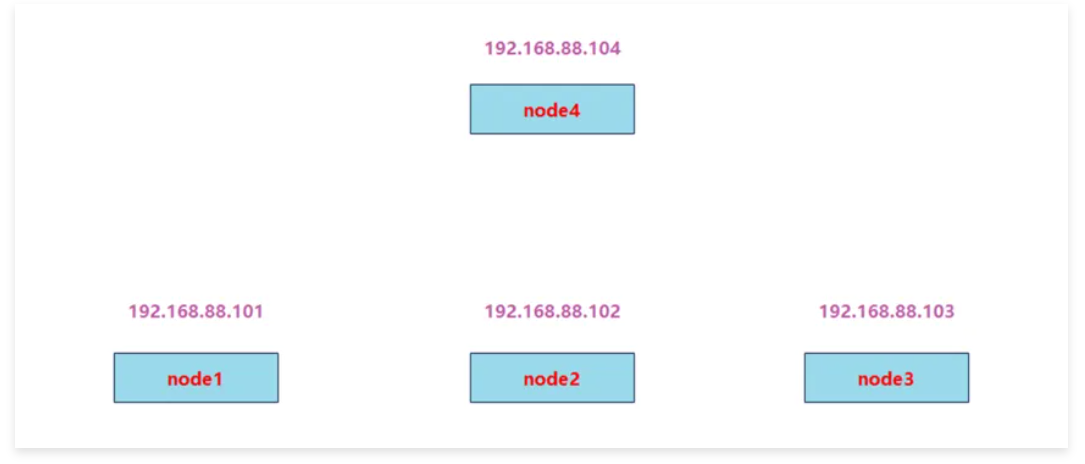
集群环境规划
准备工作:
准备四台服务器,需要能上外网,IP静态固定 (除node4外每台最少加3个磁盘,最小20G,不用分区)
如果启动后,lsblk查看不到新磁盘,可以使用如下命令:
for host in $(ls /sys/class/scsi_host) ; do echo "- - -" > /sys/class/scsi_host/$host/scan; done
注意:如果磁盘是非空的,可以使用如下方式擦除,必须保证磁盘是干净的。
# Step 1:停用 LVM 卷组
vgremove -f $(vgdisplay | grep 'VG Name' | awk '{print $3}') 2>/dev/null
# Step 2:移除 PV
pvremove -ff /dev/sda /dev/sdb /dev/sdc
# Step 3:清除文件系统签名
wipefs -a /dev/sda
wipefs -a /dev/sdb
wipefs -a /dev/sdc
# Step 4:清除 GPT 分区表
sgdisk --zap-all /dev/sda
sgdisk --zap-all /dev/sdb
sgdisk --zap-all /dev/sdc
# Step 5(可选):物理清空块设备(可能失败,但推荐尝试)
blkdiscard /dev/sda || echo "blkdiscard /dev/sda 跳过"
blkdiscard /dev/sdb || echo "blkdiscard /dev/sdb 跳过"
blkdiscard /dev/sdc || echo "blkdiscard /dev/sdc 跳过"
# Step 6:刷新内核缓存
partprobe
udevadm settle1, 配置主机名和主机名绑定(所有节点都要绑定)
(注意:这里都全改成短主机名,方便后面实验。如果你坚持用类似vm1.cluster.com这种主机名,或者加别名的话,ceph会在后面截取你的主机名vm1.cluster.com为vm1,造成不一致导致出错)
# hostnamectl set-hostname --static node1
# hostnamectl set-hostname --static node2
# hostnamectl set-hostname --static node3
# hostnamectl set-hostname --static node4
# vim /etc/hosts
192.168.120.101 node1
192.168.120.102 node2
192.168.120.103 node3
192.168.120.104 node42, 关闭防火墙,selinux(使用iptables -F清一下规则)
# systemctl stop firewalld
# systemctl disable firewalld
# iptables -F
# setenforce 03, 时间同步(启动chronyd服务并确认所有节点时间一致)
# dnf install -y chrony
# systemctl enable --now chronyd
# vi /etc/chrony.conf
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
server ntp5.aliyun.com iburst
server ntp6.aliyun.com iburst
systemctl restart chronyd
验证时间同步
# chronyc tracking4, 配置yum源(所有节点都要配置,包括client)
# dnf install -y epel-release所有节点安装必要的软件包
# dnf install -y snappy leveldb gdisk gperftools-libs podman配置清华源
tee /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=Ceph repository - Tsinghua
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-reef/el9/x86_64/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
EOF生成缓存(可选)
# dnf makecache集群部署过程
第1步: 配置ssh免密
以node1为部署配置节点,在node1上配置ssh等效性(要求ssh node1,node2,node3 ,client都要免密)
说明: 此步骤不是必要的,做此步骤的目的:
• 如果使用ceph-deploy来安装集群,免密会方便安装
• 如果不使用ceph-deploy安装,也可以方便后面操作: 比如同步配置文件
[root@node1 ~]# ssh-keygen
[root@node1 ~]# ssh-copy-id node1
[root@node1 ~]# ssh-copy-id node2
[root@node1 ~]# ssh-copy-id node3
[root@node1 ~]# ssh-copy-id node4第2步: 安装 cephadm
在node1、node2、node3和client节点上执行以下命令来安装 cephadm 工具:
curl --silent --remote-name --location https://download.ceph.com/rpm-reef/el9/noarch/cephadm
mv cephadm /usr/local/bin/
chmod +x /usr/local/bin/cephadm第3步: 初始化ceph集群
创建配置目录
在node1上创建并进入配置目录:
mkdir -p /etc/ceph
cd /etc/ceph初始化集群
使用cephadm初始化 Ceph 集群(node1作为监控节点):
[root@node1 ~]# cephadm bootstrap --mon-ip 192.168.120.101
------------------------------------------------------------------------------------------
Ceph Dashboard is now available at:
URL: https://node1:8443/
User: admin
Password: eva96cxdwf
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/84fd400a-d64c-11f0-9ecf-000c2970fa83/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/local/bin/cephadm shell --fsid 84fd400a-d64c-11f0-9ecf-000c2970fa83 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/local/bin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/en/latest/mgr/telemetry/
Bootstrap complete.这一部分结束,最好给node1、node2、node3、node4拍摄一个快照
第4步: 检查集群状态
使用以下命令查看集群的健康状态:
dnf install ceph-common -y
ceph -s如果集群正常启动,将看到类似下面的输出:
cluster:
id: 84fd400a-d64c-11f0-9ecf-000c2970fa83
health: HEALTH_OK
services:
mon: 1 daemons, quorum node1
osd: 0 osds: 0 up, 0 in
mgr: node1(active)第5步: 添加 OSD 节点
把集群公钥复制到将成为集群成员的节点
[root@node1 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
[root@node1 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@node3
[root@node1 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@node4添加节点node2,node3,node4(各节点要先安装python3, podman)
[root@node1 ~]# ceph orch host add node2 192.168.120.102
[root@node1 ~]# ceph orch host add node3 192.168.120.103
[root@node1 ~]# ceph orch host add node4 192.168.120.104
[root@node1 ~]# ceph orch host ls
HOST ADDR LABELS STATUS
node1 192.168.120.101 _admin
node2 192.168.120.102
node3 192.168.120.103
node4 192.168.120.104
4 hosts in cluster注:如果操作错了
ceph orch host rm node3给node1、node4打上管理员标签,拷贝ceph配置文件和keyring到node4
[root@node1 ~]# ceph orch host label add node1 _admin
[root@node1 ~]# ceph orch host label add node4 _admin
[root@node1 ~]# scp /etc/ceph/{*.conf,*.keyring} root@node4:/etc/ceph
[root@node1 ~]# ceph orch host ls第6步: 配置管理节点(MGR)
[root@node1 ~]# ceph orch apply mgr --placement="node1,node2,node3"作用:用来安装、配置、管理和监控Ceph集群,运行ceph命令、dashboard、集群编排等管理操作
特点:通常是你登录运维操作的节点,可以与其他服务节点共用(如mon、mgr),也可以单独设立
不是Ceph集群核心组件,但对日常维护必不可少
第7步: 配置监控节点(MON)
[root@node1 ~]# ceph orch apply mon "node1,node2,node3"作用:负责维护集群的健康状态、监控集群各节点服务,并保存集群的元数据(如集群成员、认证信息、服务状态等),是Ceph集群的大脑
特点:至少需要1个(生产建议3个奇数个),所有客户端、OSD、MGR等组件都要和MON通信,保障集群一致性和高可用
第8步: 创建存储池(OSD)
有坑:不同的VMware版本,可能添加磁盘时,产生的磁盘名称不一致
VMware16
第一块盘:sdb
第二块盘:sdc
第三块盘:sdd
VMware17
第一块盘:sda
第二块盘:sdb
第三块盘:sdc
具体添加盘对应是设备名称,可以通过lsblk来进行查看!!!
[root@node1 ~]# ceph orch daemon add osd node1:/dev/sdb
[root@node1 ~]# ceph orch daemon add osd node1:/dev/sdc
[root@node1 ~]# ceph orch daemon add osd node1:/dev/sdd
[root@node1 ~]# ceph orch daemon add osd node2:/dev/sdb
[root@node1 ~]# ceph orch daemon add osd node2:/dev/sdc
[root@node1 ~]# ceph orch daemon add osd node2:/dev/sdd
[root@node1 ~]# ceph orch daemon add osd node3:/dev/sdb
[root@node1 ~]# ceph orch daemon add osd node3:/dev/sdc
[root@node1 ~]# ceph orch daemon add osd node3:/dev/sdd
或者:
[root@node1 ~]# for i in node1 node2 node3; do for j in sda sdb sdc; do ceph orch daemon add osd $i:/dev/$j; done; done
[root@node1 ~]# ceph orch device ls
如果磁盘无法添加,报错,提示磁盘非空,可以考虑使用如下脚本清理所有磁盘:disk_clean.sh
#!/bin/bash
DISKS=("/dev/sda" "/dev/sdb" "/dev/sdc")
echo "==== 开始清理 Ceph OSD 磁盘 ===="
# 尝试移除 LVM 卷组
VG_LIST=$(vgdisplay 2>/dev/null | grep 'VG Name' | awk '{print $3}')
if [[ -n "$VG_LIST" ]]; then
for vg in $VG_LIST; do
echo "[INFO] 尝试移除卷组 $vg ..."
vgremove -f "$vg"
done
fi
# 遍历每个磁盘
for DISK in "${DISKS[@]}"; do
echo ">>> 处理磁盘: $DISK"
echo "[1] 执行 wipefs ..."
wipefs -a "$DISK"
echo "[2] 执行 sgdisk --zap-all ..."
sgdisk --zap-all "$DISK"
echo "[3] 执行 pvremove ..."
pvremove -ff "$DISK"
echo "[4] 尝试 blkdiscard(可能失败可忽略)..."
blkdiscard "$DISK" || echo "[WARN] $DISK 不支持 blkdiscard 或失败,已忽略"
echo "✔ $DISK 清理完成"
echo "----------------------------"
done
# 刷新内核分区表
echo "[5] 刷新内核分区表 ..."
partprobe
udevadm settle
# 刷新 Ceph 设备状态(需在 cephadm shell 中手动执行)
echo "⚠️ 请进入 cephadm shell 并执行:ceph orch device ls --refresh"
echo "✅ 所有磁盘已清理完成!"登录ceph web界面:
https://192.168.120.101:8443/#/dashboard
设置密码
echo "admin888" > /tmp/admin_pass.txt
ceph dashboard set-login-credentials admin -i /tmp/admin_pass.txt
rm -f /tmp/admin_pass.txt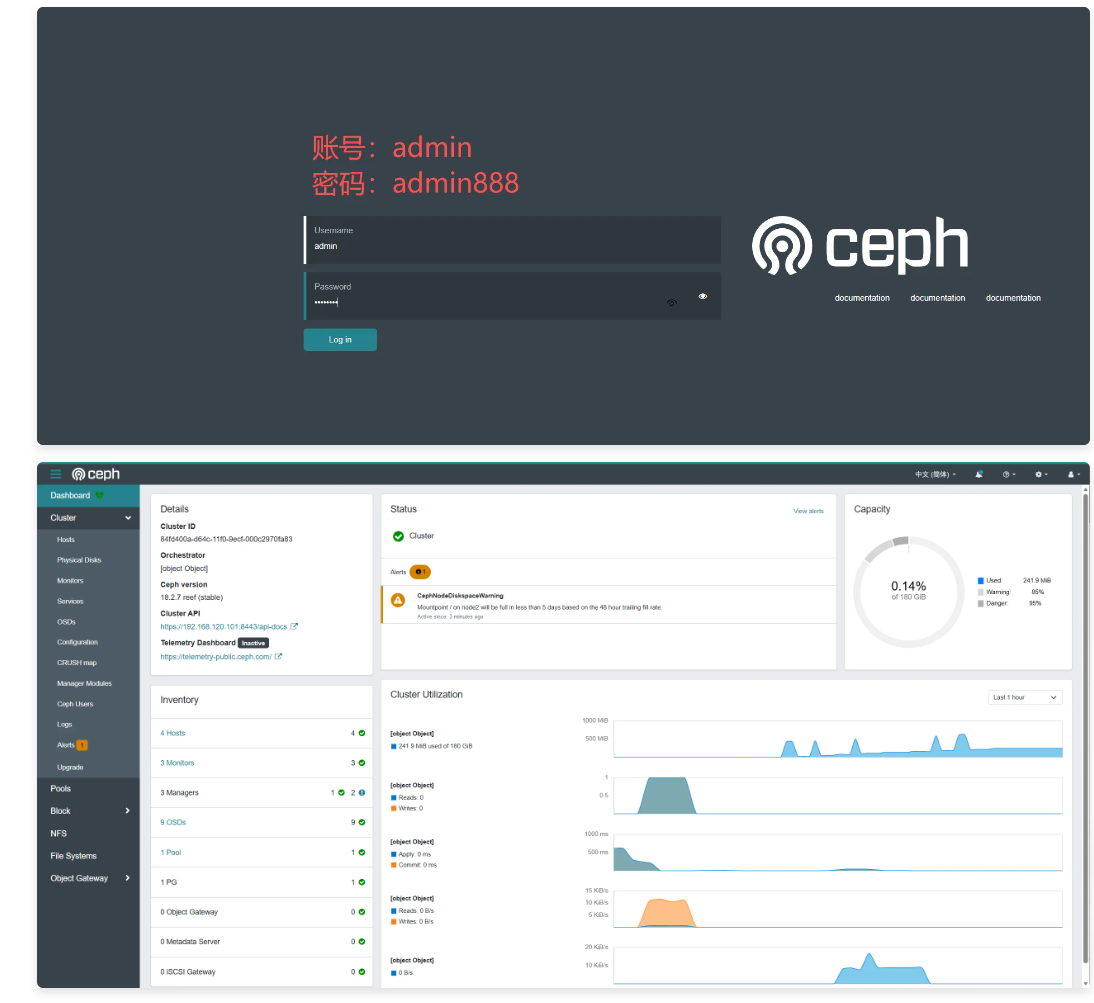
至此,ceph集群部署完毕!
[root@node1 ~]# ceph -s
cluster:
id: 84fd400a-d64c-11f0-9ecf-000c2970fa83
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node3,node2 (age 5m)
mgr: node1.pzvtui(active, since 18m), standbys: node3.lbaxnq, node2.ohzhyb
osd: 9 osds: 9 up (since 3m), 9 in (since 4m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 242 MiB used, 180 GiB / 180 GiB avail
pgs: 1 active+clean
如果异常,可以快速恢复:
#!/bin/bash
echo "▶️ 步骤 1:同步时间,确保 NTP 启用..."
dnf install -y chrony
systemctl enable --now chronyd
chronyc tracking
echo "✅ 时间同步完成"
echo "▶️ 步骤 2:重启 MON 容器服务..."
ceph orch restart mon.node1
sleep 15
echo "✅ 容器重启完成,尝试获取集群状态..."
ceph -s第9步:node4节点管理ceph
# 之前已经将ceph配置文件和keyring拷贝到node4节点
[root@node4 ~]# ceph -s
-bash: ceph: 未找到命令,需要安装ceph-common
# 安装ceph源
[root@node4 ~]# tee /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=Ceph repository - Tsinghua
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-reef/el9/x86_64/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.tuna.tsinghua.edu.cn/ceph/keys/release.asc
EOF
# 安装ceph-common
[root@node4 ~]# yum -y install ceph-common
[root@node4 ~]# ceph -s
cluster:
id: 84fd400a-d64c-11f0-9ecf-000c2970fa83
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node3,node2 (age 9m)
mgr: node1.pzvtui(active, since 23m), standbys: node3.lbaxnq, node2.ohzhyb
osd: 9 osds: 9 up (since 8m), 9 in (since 9m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 242 MiB used, 180 GiB / 180 GiB avail
pgs: 1 active+clean重置集群(了解,不需要操作)
1,获取fsid
ceph -s
-------------------------------------------------
cluster:
id: 84fd400a-d64c-11f0-9ecf-000c2970fa83
health: HEALTH_OK
...2, 然后使用这个fsid来执行rm-cluster命令:
cephadm rm-cluster --fsid 84fd400a-d64c-11f0-9ecf-000c2970fa83 --force如果你不想保留日志文件或者想同时擦除 OSD 磁盘,可以加上其他选项:
cephadm rm-cluster --fsid 84fd400a-d64c-11f0-9ecf-000c2970fa83 --force --keep-logs --zap-osds
--keep-logs:保留日志文件。
--zap-osds:在清理过程中擦除所有 OSD 磁盘。
执行此命令后,Ceph 集群将被完全删除,准备重新初始化。还可以通过:
podman stop $(podman ps -a -q)
rm -rf /etc/ceph/*
rm -rf /var/lib/ceph/*
rm -rf /var/log/ceph/*
rm -rf /var/run/ceph/*彻底擦除磁盘信息(了解,不需要操作)
#!/bin/bash
# 磁盘列表
DISKS=("/dev/sda" "/dev/sdb" "/dev/sdc")
# 确保磁盘未挂载
for DISK in "${DISKS[@]}"; do
if mount | grep "$DISK" > /dev/null; then
echo "Unmounting $DISK"
umount "$DISK"
fi
done
# 清除每个磁盘的文件系统签名
for DISK in "${DISKS[@]}"; do
echo "Clearing filesystem signatures on $DISK"
wipefs -a "$DISK" && echo "$DISK: File system signatures removed successfully."
done
# 刷新磁盘表
for DISK in "${DISKS[@]}"; do
partprobe "$DISK"
echo "Disk table for $DISK reloaded."
done
# 删除每个磁盘的分区表并创建新的空 GPT 分区表
for DISK in "${DISKS[@]}"; do
echo "Removing partition table and creating new GPT partition table on $DISK"
parted "$DISK" --script mklabel gpt && echo "$DISK: Partition table removed and new GPT partition table created."
done
# 确认磁盘没有分区
for DISK in "${DISKS[@]}"; do
echo "Verifying partition table for $DISK"
parted "$DISK" print
done
# 使用 dd 清除磁盘,避免 "No space left on device" 错误
for DISK in "${DISKS[@]}"; do
echo "Zeroing out data on $DISK (this may take a while)"
# 使用较小的块大小避免写入磁盘末尾
dd if=/dev/zero of="$DISK" bs=1M count=20480 status=progress
echo "$DISK: Data wiped successfully."
done
# 再次确认磁盘是否已经清理
for DISK in "${DISKS[@]}"; do
echo "Final verification of $DISK"
lsblk "$DISK"
blkid "$DISK"
done
echo "Disks cleaned: ${DISKS[@]}"建议:如果磁盘重置以后,可能不会马上生效,我们可以通过reboot重启来实现清理磁盘
osd都创建好了,那么怎么存取数据?
集群节点的扩容方法
假设再加一个新的集群节点node4
1, 主机名配置和绑定
2, 安装必备软件 sudo dnf install -y snappy leveldb gdisk gperftools-libs podman
3, 配置免密以及拷贝集群证书到node4
[root@node1 ~]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@node4
[root@node1 ~]# scp /etc/ceph/{ceph.conf,ceph.client.admin.keyring} root@node4:/etc/ceph/4, 在node1服务器,将node4添加到集群中
ceph orch host add node4 192.168.120.104
ceph orch host label rm node4 _no_schedule
ceph orch host label rm node4 _no_conf_keyring
注意:
① ceph orch host label rm node4 _no_schedule
移除节点node4上的特殊标签 _no_schedule。
标签 _no_schedule 表示禁止在这个节点上调度部署新的守护进程或服务。
移除此标签意味着允许 Ceph 在节点 node4 上部署或调度服务和守护进程。
② ceph orch host label rm node4 _no_conf_keyring
移除节点node4上的特殊标签 _no_conf_keyring。
标签 _no_conf_keyring 表示 Ceph 不会自动在该节点上部署 Ceph 配置文件和认证密钥环。
移除此标签意味着允许 Ceph 自动将配置文件和密钥环分发到节点 node4,以便节点能正常加入集群并运行 Ceph 服务。5, 按需求选择在node4上添加mon或mgr或osd等
ceph orch apply mon "node1,node2,node3,node4"
ceph orch apply mgr --placement="node1,node2,node3,node4"
ceph orch daemon add osd node4:/dev/sda
# 如果这个机器上有多个磁盘,可以依次添加(暂不执行)
# ceph orch daemon add osd node4:/dev/sdb
# ceph orch daemon add osd node4:/dev/sdc
scp /etc/ceph/{ceph.conf,ceph.client.admin.keyring} root@node4:/etc/ceph集群节点的缩容方法(了解)
假设要从ceph集群中移除node3
1, 查看ceph集群osd使用情况
[root@node1 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17537 root default
-3 0.05846 host node1
0 hdd 0.01949 osd.0 up 1.00000 1.00000
1 hdd 0.01949 osd.1 up 1.00000 1.00000
2 hdd 0.01949 osd.2 up 1.00000 1.00000
-5 0.05846 host node2
3 hdd 0.01949 osd.3 up 1.00000 1.00000
4 hdd 0.01949 osd.4 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
-7 0.05846 host node3
6 hdd 0.01949 osd.6 up 1.00000 1.00000
7 hdd 0.01949 osd.7 up 1.00000 1.00000
8 hdd 0.01949 osd.8 up 1.00000 1.000002,从ceph集群移除osd
假设node3上的 OSD 为osd.6、osd.7和osd.8,你可以使用以下命令将它们标记为out
ceph osd stop osd.6
ceph osd stop osd.7
ceph osd stop osd.8
ceph osd out osd.6
ceph osd out osd.7
ceph osd out osd.8删除osd
ceph osd rm osd.6
ceph osd rm osd.7
ceph osd rm osd.8删除osd秘钥
ceph auth del osd.6
ceph auth del osd.7
ceph auth del osd.8删除crush
ceph osd crush remove osd.6
ceph osd crush remove osd.7
ceph osd crush remove osd.83, 移除node3作为 MON 和 MGR 节点
ceph mon stat
ceph mon remove node3
ceph mgr stat
ceph mgr remove node34, 移除node3节点
ceph orch host drain node3
ceph orch ps
ceph orch apply mgr --placement="node1,node2,node4"
ceph orch apply mon --placement="node1,node2,node4"
ceph orch host drain node3 --force5, 清理node3上的 Ceph 配置和服务
rm -rf /etc/ceph/*6, 确认集群状态
ceph osd tree
ceph mon stat
ceph mgr stat7, 清理磁盘
在确认 OSD 守护进程已经被移除后,可以删除 LVM 相关的物理卷和卷组。
pvs
vgs
lvs删除逻辑卷
lvremove /dev/ceph-151309b5-3a55-4e3a-93a5-d5d7446bd764
lvremove /dev/ceph-27e023bb-a3d2-40a6-a3ad-b4647833bff8
lvremove /dev/ceph-315c1b17-f293-4fab-b25d-47299b857881删除卷组
vgremove ceph-151309b5-3a55-4e3a-93a5-d5d7446bd764
vgremove ceph-27e023bb-a3d2-40a6-a3ad-b4647833bff8
vgremove ceph-315c1b17-f293-4fab-b25d-47299b857881删除物理卷
pvremove /dev/sdb
pvremove /dev/sdc
pvremove /dev/sdd清理磁盘
wipefs /dev/sdb
wipefs /dev/sdc
wipefs /dev/sdd四、RADOS原生数据存取演示
上面提到了RADOS也可以进行数据的存取操作, 但我们一般不直接使用它,但我们可以先用RADOS的方式来深入了解下ceph的数据存取原理。
存取原理
要实现数据存取需要创建一个pool,创建pool要先分配PG。
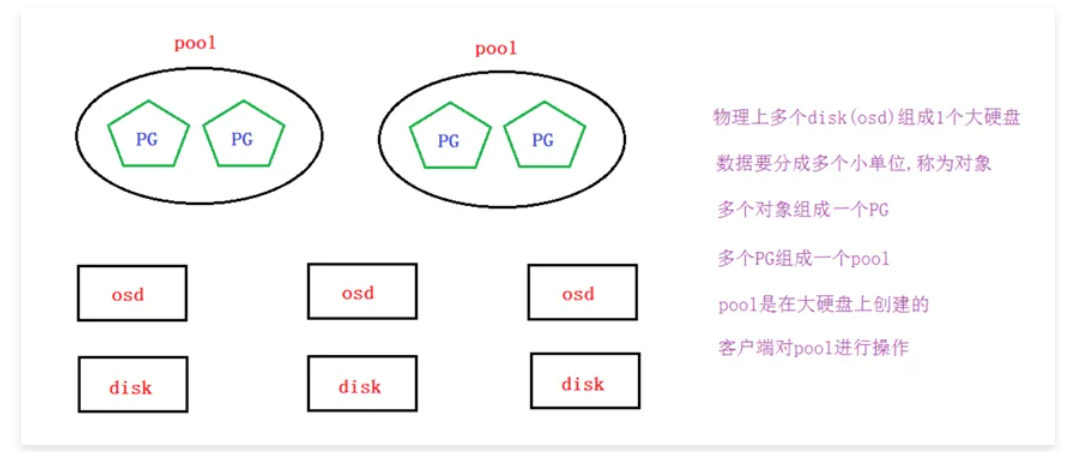
如果客户端对一个pool写了一个文件, 那么这个文件是如何分布到多个节点的磁盘上呢?
答案是通过CRUSH算法。
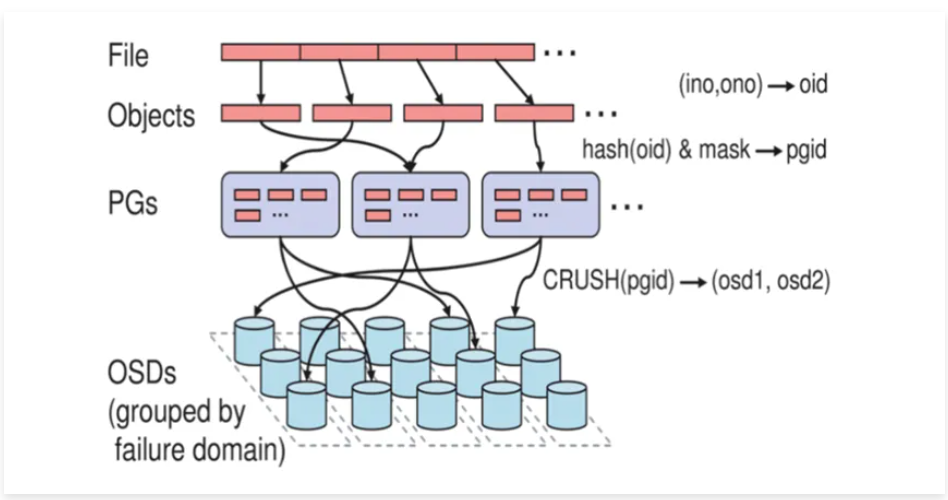
CRUSH算法
• CRUSH(Controlled Scalable Decentralized Placement of Replicated Data)算法为可控的,可扩展的,分布式的副本数据放置算法的简称。
• PG到OSD的映射的过程算法叫做CRUSH 算法。(一个Object需要保存三个副本,也就是需要保存在三个osd上)。
• CRUSH算法是一个伪随机的过程,他可以从所有的OSD中,随机性选择一个OSD集合,但是同一个PG每次随机选择的结果是不变的,也就是映射的OSD集合是固定的。
生活中的案例类比:
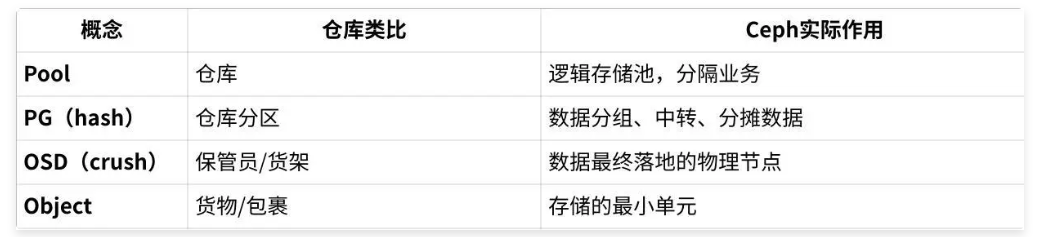
假设你要存一个包裹
选定仓库(Pool):
我要把这批货物存到‘服装仓库。
分配到某个分区(PG):
仓库有很多分区(比如128个),仓库管理员(Ceph)用某种算法决定,这个包裹应该归到2区。
分区决定包裹交给哪些保管员/货架(OSD):
2区有三个保管员在负责(副本数为3),包裹分别存给A、B、C三个保管员,每人一份副本(这样即使A出问题,B和C还能找回)。
真正落地到保管员(OSD)手里:
保管员把货物放到自己的货架上,负责任何时候都能找出来。
小结:
• 客户端直接对pool操作(但文件存储,块存储,对象存储我们不这么做)
• pool里要分配PG
• PG里可以存放多个对象
• 对象就是由客户端写入的数据分离的单位
• CRUSH算法将客户端写入的数据映射分布到OSD,从而最终存放到物理磁盘上(这个具体过程是抽象的,我们运维工程师可不用再深挖,因为分布式存储对于运维工程师来说就一个大硬盘)
创建pool
创建test_pool,指定pg数为128
[root@node1 ~]# ceph osd pool create test_pool 128
pool 'test_pool' created查看pg数量,可以使用ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
[root@node1 ~]# ceph osd pool get test_pool pg_num
pg_num: 127
#Ceph的PG自动缩放功能(Autoscaler)被启用,导致PG数量被动态调整
[root@node1 ~]# ceph osd pool ls detail | grep test_pool
pool 2 'test_pool' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 72 pgp_num 70 pg_num_target 32 pgp_num_target 32 autoscale_mode on last_change 300 lfor 0/296/294 flags hashpspool stripe_width 0 read_balance_score 1.63
Ceph的 PG自动缩放功能(从Mimic版本引入)会根据集群规模(OSD数量、池大小等)自动计算最优PG数量,并通过调整pg_num/pgp_num趋近于目标值(pg_num_target/pgp_num_target)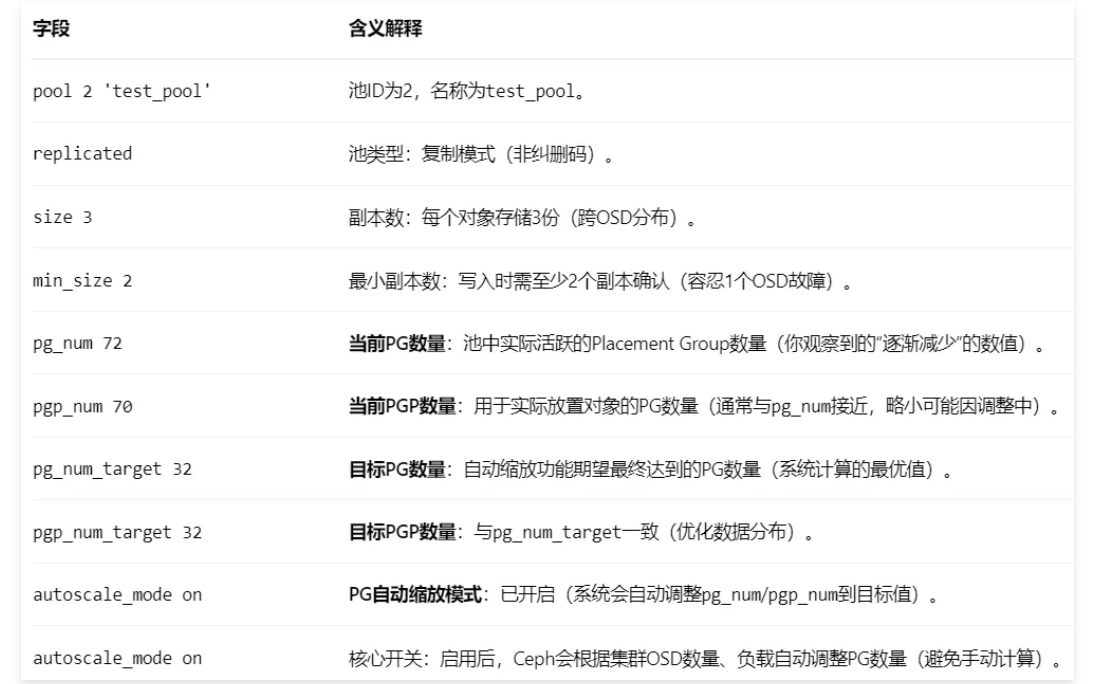
说明: pg数与ods数量有关系
• pg数为2的倍数,一般5个以下osd,分128个PG或以下即可(分多了PG会报错的,可按报错适当调低)
• 可以使用ceph osd pool set test_pool pg_num 64这样的命令来尝试调整
PG(Placement Group)数量计算公式
总 PG ≈ (OSD 数 × 100) / 副本数
# osd数量
ceph osd ls
# 查看 pool 的副本数
ceph osd pool get <pool名称> size
# 思考:osd为10,副本为3,pool设置多大合适?
总 PG ≈ (10 × 100) / 3 ≈ 333
# 单个 pool 应该设置多少 PG?
答:如果你的集群只有一个 pool,那直接设置 pool 的 PG 数为 333 或 320(取 2 的幂次方更佳)
# 为什么取2的幂次方?
答:PG 数通常建议取 2 的幂(64, 128, 256, 512等),这样数据分布更均衡、后期扩容更方便
# 多个 pool 应该设置多少 PG?
答:如果你有多个 pool,总 PG 数需要在所有 pool 之间分配,比如有2个 pool,可以一个设置 192,另一个 128,两个加起来接近 320~333存储测试
1, 我这里把本机的/etc/fstab文件上传到test_pool,并取名为newfstab
[root@node1 ~]# rados put newfstab /etc/fstab --pool=test_pool2, 查看
[root@node1 ~]# rados -p test_pool ls
newfstab3, 删除
[root@node1 ~]# rados rm newfstab --pool=test_pool删除pool
在部署节点node1上增加参数允许ceph删除pool
ceph config set mon mon_allow_pool_delete true
ceph osd pool delete test_pool test_pool --yes-i-really-really-mean-it
ceph osd pool ls
ceph health detail五、创建Ceph文件存储
在所有操作系统中,文件通常分为两部分:① 数据(文件具体内容) ② 元数据(文件目录结构、权限、属性)
在 Ceph 集群中,MDS(Metadata Server)是负责管理 Ceph 文件系统(CephFS)元数据的服务,负责处理文件系统的目录结构、文件操作等元数据相关的任务。要部署 MDS 服务,以下是使用cephadm部署 MDS 的步骤。
创建文件存储并使用
第1步: 准备 Ceph 集群
[root@node1 ~]# ceph -s
cluster:
id: 84fd400a-d64c-11f0-9ecf-000c2970fa83
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node3,node2 (age 105m)
mgr: node1.pzvtui(active, since 118m), standbys: node3.lbaxnq, node2.ohzhyb
osd: 9 osds: 9 up (since 103m), 9 in (since 104m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 642 MiB used, 179 GiB / 180 GiB avail
pgs: 1 active+clean第2步: 为了运行 Ceph 文件系统(CephFS),需要至少两个 RADOS 池,一个用于数据(data pool),另一个用于元数据(metadata pool)
创建数据池和元数据池
实际数据与元数据,对应的PG数量对比,一般建议2/1、4/1、8/1
数据仓库:128个
元数据仓库:32 或 16个
比如一个文件128MB,但是元数据(文件目录结构、权限、属性)=> 16MB
[root@node1 ~]# ceph osd pool create cephfs_data 128
pool 'cephfs_data' created
[root@node1 ~]# ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created查看池是否创建成功
[root@node1 ~]# ceph osd pool ls
.mgr
cephfs_data
cephfs_metadata第3步: 创建Ceph文件系统,并确认客户端访问的节点
基本语法:
ceph fs new <文件系统名称> cephfs_metadata cephfs_data
[root@node1 ~]# ceph fs new cephfs cephfs_metadata cephfs_data
[root@node1 ~]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@node1 ~]# ceph health detail第4步:创建mds服务
MDS的核心作用:集中管理“元数据”
MDS是CephFS的“大脑”,专门解决元数据的集中管理、高性能访问与强一致性难题。
[root@node1 ~]# ceph orch apply mds cephfs
[root@node1 ~]# ceph mds statcephfs文件系统已经有 1 个 MDS 守护进程在运行并处于active状态。
另一个 MDS 守护进程处于standby状态,表示它已经启动,但目前不是主工作节点。
我们也可以调整mds数量
# 增加备用节点
[root@node1 ~]# ceph fs set cephfs max_mds 3
[root@node1 ~]# ceph fs set cephfs standby_count_wanted 1
[root@node1 ~]# ceph orch apply mds cephfs --placement="node1,node2,node3"ceph fs set cephfs max_mds 3这个命令的作用是将文件系统cephfs的max_mds参数设置为 3,允许最多启动 3 个 MDS 守护进程。这本身是修改 Ceph 配置文件的操作,不会立即部署新的 MDS 守护进程。
第5步: 客户端准备验证key文件
• 说明: ceph默认启用了cephx认证, 所以客户端的挂载必须要验证
在集群节点(node1,node2,node3)上任意一台查看密钥字符串
[root@node1 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQAVTzppHThHIhAAv+MLxBwKjfqqX0SGPkz2dQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"在客户端上创建一个文件记录密钥字符串
# 创建一个密钥文件,复制粘贴上面得到的字符串
[root@node4 ~]# vim admin.key
AQAVTzppHThHIhAAv+MLxBwKjfqqX0SGPkz2dQ==第6步: 客户端挂载(挂载ceph集群中跑了mon监控的节点, mon监控为6789端口)
[root@node4 ~]# mount -t ceph node1:6789:/ /mnt -o name=admin,secretfile=/root/admin.key第7步: 验证
# 大小不用在意,场景不一样,pg数,副本数都会影响
[root@node4 ~]# df -h |tail -1
192.168.120.101:6789:/ 57G 0 57G 0% /mnt如要验证读写请自行验证
可以使用两个客户端, 同时挂载此文件存储,可实现同读同写
[root@node4 ~]# cp /etc/passwd /mnt/
[root@node4 ~]# ls /mnt/
passwd删除文件存储方法
如果需要删除文件存储,请按下面操作过程来操作
第1步: 在客户端上删除数据,并umount所有挂载
[root@node4 ~]# rm /mnt/* -rf
[root@node4 ~]# umount /mnt/第2步: 回到集群任意一个节点上(node1,node2,node3其中之一)删除
[root@node4 ~]# ceph fs fail cephfs
[root@node4 ~]# ceph fs rm cephfs --yes-i-really-mean-it
[root@node4 ~]# ceph osd pool delete cephfs_metadata cephfs_metadata --yes-i-really-really-mean-it
[root@node4 ~]# ceph osd pool delete cephfs_data cephfs_data --yes-i-really-really-mean-it六、创建Ceph块存储
创建块存储并使用
第1步: 在node1上同步配置文件到client节点(node4)
[root@node1 ~]# scp /etc/ceph/{*.conf,*.keyring} root@node4:/etc/ceph第2步:建立存储池,并初始化
注意:在客户端操作
[root@node4 ~]# ceph osd pool create rbd_pool 128
[root@node4 ~]# rbd pool init rbd_pool第3步:创建一个存储卷(我这里卷名为volume1,大小为5000M)
注意: volume1的专业术语为image, 我这里叫存储卷方便理解
[root@node4 ~]# rbd create volume1 --pool rbd_pool --size 5000
[root@node4 ~]# rbd ls rbd_pool
[root@node4 ~]# rbd info volume1 -p rbd_pool
rbd image 'volume1':
# 可以看到volume1为rbd image
size 4.9 GiB in 1250 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: 3954c14d3be6
block_name_prefix: rbd_data.3954c14d3be6
format: 2
# 格式有1和2两种,现在是2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Thu Dec 11 15:23:46 2025
access_timestamp: Thu Dec 11 15:23:46 2025
modify_timestamp: Thu Dec 11 15:23:46 2025第4步: 将创建的卷映射成块设备
[root@node4 ~]# rbd map rbd_pool/volume1
/dev/rbd0第5步: 查看映射(如果要取消映射, 可以使用rbd unmap /dev/rbd0)
[root@node4 ~]# rbd showmapped
id pool namespace image snap device
0 rbd_pool volume1 - /dev/rbd0第6步: 格式化,挂载
[root@node4 ~]# mkfs.xfs /dev/rbd0
[root@node4 ~]# mount /dev/rbd0 /mnt/
[root@node4 ~]# df -h |tail -1
/dev/rbd0 4.9G 67M 4.8G 2% /mnt可自行验证读写
注意: 块存储是不能实现同读同写的,请不要两个客户端同时挂载进行读写
块存储扩容与裁减
在线扩容
经测试,分区后/dev/rbd0p1不能在线扩容,直接使用/dev/rbd0才可以
# 扩容成8000M
[root@node4 ~]# rbd resize --size 8000 rbd_pool/volume1
Resizing image: 100% complete...done.
[root@node4 ~]# rbd info rbd_pool/volume1 |grep size
size 7.8 GiB in 2000 objects
# 查看大小,并没有变化
[root@node4 ~]# df -h |tail -1
/dev/rbd0 4.9G 67M 4.8G 2% /mnt
[root@node4 ~]# xfs_growfs -d /mnt/
# 再次查看大小,在线扩容成功
[root@node4 ~]# df -h |tail -1
/dev/rbd0 7.8G 89M 7.7G 2% /mnt块存储裁减
不能在线裁减.裁减后需重新格式化再挂载,所以请提前备份好数据.
# 再裁减回5000M
[root@node4 ~]# rbd resize --size 5000 rbd_pool/volume1 --allow-shrink
# 重新格式化挂载
[root@node4 ~]# umount /mnt/
[root@node4 ~]# mkfs.xfs -f /dev/rbd0
[root@node4 ~]# mount /dev/rbd0 /mnt/
# 再次查看,确认裁减成功
[root@client ~]# df -h |tail -1
/dev/rbd0 4.9G 33M 4.9G 1% /mnt删除块存储方法
[root@client ~]# umount /mnt/
[root@client ~]# rbd unmap /dev/rbd0
[root@client ~]# ceph osd pool delete rbd_pool rbd_pool --yes-i-really-really-mean-it七、Ceph对象存储
测试ceph对象网关的连接
第1步: 在node1上创建rgw
[root@node1 ~]# ceph orch apply rgw myrealm myzone --placement="node1"
注:默认端口为80,如果需要修改可以参考如下方式
ceph orch apply rgw myrealm myzone --placement="node1" --port 7480
myrealm(领域) 就像是一个大范围的名字,代表一套对象存储的大环境,比如整个公司或者整个项目的存储系统。
myzone(区域) 是这个大环境里面的一个小区域,比如某个具体的数据中心或者机房,用来实际放 RGW 的地方。
[root@node1 ~]# ceph -s
cluster:
id: 84fd400a-d64c-11f0-9ecf-000c2970fa83
health: HEALTH_OK
services:
mon: 3 daemons, quorum node1,node3,node2 (age 2h)
mgr: node1.pzvtui(active, since 2h), standbys: node3.lbaxnq, node2.ohzhyb
osd: 9 osds: 9 up (since 2h), 9 in (since 2h)
rgw: 1 daemon active (1 hosts, 1 zones)
data:
pools: 5 pools, 5 pgs
objects: 193 objects, 454 KiB
usage: 986 MiB used, 179 GiB / 180 GiB avail
pgs: 5 active+clean
io:
client: 57 KiB/s rd, 4.3 KiB/s wr, 86 op/s rd, 50 op/s wr
[root@node1 ~]# ceph osd pool ls
.mgr
.rgw.root
default.rgw.log
default.rgw.control
default.rgw.meta第2步: 在客户端测试连接对象网关
[root@node1 ~]# radosgw-admin user create --uid=s3 --display-name="object_storage" --system
{
"user_id": "s3",
"display_name": "object_storage",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "s3",
"access_key": "JEMKLRGQZRFAGEXABM0R",
"secret_key": "fIRljwrFxgn4AIfxU0vDtLsJErHNOFiiyMfHvgsC"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"system": true,
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}上面一大段主要有用的为access_key与secret_key,用于连接对象存储网关
[root@node1 ~]# radosgw-admin user info --uid=s3 | grep -E 'access_key|secret_key'
"access_key": "JEMKLRGQZRFAGEXABM0R",
"secret_key": "fIRljwrFxgn4AIfxU0vDtLsJErHNOFiiyMfHvgsC"S3连接ceph对象网关
Amazon S3是一种面向Internet的对象存储服务.我们这里可以使用s3工具连接ceph的对象存储进行操作
第1步: 客户端安装s3cmd工具,并编写ceph连接配置文件
[root@node4 ~]# yum install s3cmd -y
# 创建并编写下面的文件,key文件对应前面创建测试用户的key
[root@node4 ~]# s3cmd --configure
Enter new values or accept defaults in brackets with Enter.
Refer to user manual for detailed description of all options.
Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables.
Access Key: JEMKLRGQZRFAGEXABM0R
Secret Key: fIRljwrFxgn4AIfxU0vDtLsJErHNOFiiyMfHvgsC
Default Region [US]:
Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3.
S3 Endpoint [s3.amazonaws.com]: 192.168.120.101:80
Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used
if the target S3 system supports dns based buckets.
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 192.168.120.101:80/%(bucket)s
Encryption password is used to protect your files from reading
by unauthorized persons while in transfer to S3
Encryption password: #直接回车
Path to GPG program [/usr/bin/gpg]: #直接回车
When using secure HTTPS protocol all communication with Amazon S3
servers is protected from 3rd party eavesdropping. This method is
slower than plain HTTP, and can only be proxied with Python 2.7 or newer
Use HTTPS protocol [Yes]: No
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
HTTP Proxy server name: #直接回车
New settings:
Access Key: JEMKLRGQZRFAGEXABM0R
Secret Key: fIRljwrFxgn4AIfxU0vDtLsJErHNOFiiyMfHvgsC
Default Region: US
S3 Endpoint: 192.168.120.101:80
DNS-style bucket+hostname:port template for accessing a bucket: 192.168.120.101:80/%(bucket)s
Encryption password:
Path to GPG program: /usr/bin/gpg
Use HTTPS protocol: False
HTTP Proxy server name:
HTTP Proxy server port: 0
Test access with supplied credentials? [Y/n] Y
Please wait, attempting to list all buckets...
Success. Your access key and secret key worked fine :-)
Now verifying that encryption works...
Not configured. Never mind.
Save settings? [y/N] y
Configuration saved to '/root/.s3cfg'第2步: 命令测试
# 新建一个bucket桶
[root@node4 ~]# s3cmd mb s3://test_bucket
# 上传文件到桶
[root@node4 ~]# s3cmd put /etc/fstab s3://test_bucket
upload: '/etc/fstab' -> 's3://test_bucket/fstab' [1 of 1]
579 of 579 100% in 2s 211.59 B/s done
# 下载到当前目录
[root@node4 ~]# s3cmd get s3://test_bucket/fstab
download: 's3://test_bucket/fstab' -> './fstab' [1 of 1]
579 of 579 100% in 0s 12.84 KB/s done
[root@node4 ~]# ls
admin.key anaconda-ks.cfg fstab
# 列出bucket
[root@node4 ~]# s3cmd ls
2025-12-11 07:40 s3://test_bucket
# 列出桶内所有对象/子目录
[root@node4 ~]# s3cmd ls s3://test_bucket
2025-12-11 07:41 579 s3://test_bucket/fstab
# 删除桶内所有对象和子目录(递归删除)
[root@node4 ~]# s3cmd del s3://test_bucket/*
delete: 's3://test_bucket/fstab'
# 删除空桶
[root@node4 ~]# s3cmd rb s3://test_bucket
Bucket 's3://test_bucket/' removed
# 更多命令请见参考命令帮助
[root@client ~]# s3cmd --help八、项目部署实践:ceph+nextcloud打造私有云盘
前期规划

创建bucket
在ceph的客户端上准备好bucket和相关的连接key
[root@node4 ~]# s3cmd mb s3://next_cloud
Bucket 's3://next_cloud/' created
[root@node4 ~]# cat /root/.s3cfg
...
# 确保以下两行没问题,其他不动
access_key = JEMKLRGQZRFAGEXABM0R
secret_key = fIRljwrFxgn4AIfxU0vDtLsJErHNOFiiyMfHvgsCnextcloud环境准备
在client端安装nextcloud云盘运行所需要的web环境
nextcloud需要web服务器和php支持. 目前最新版本nextcloud需要php8.2版本,在这里我们为了节省时间,使用rpm版安装
[root@node4 ~]# dnf install -y epel-release
[root@node4 ~]# dnf module reset php -y
[root@node4 ~]# dnf module enable php:8.2 -y
[root@node4 ~]# yum install httpd mod_ssl php-mysqlnd php php-gd php-xml php-mbstring php-pecl-zip php-intl php-process -y
[root@node4 ~]# systemctl restart httpd部署nextcloud
上传nextcloud软件包, 并解压到httpd家目录
[root@node4 ~]# wget https://download.nextcloud.com/server/releases/latest.tar.bz2
[root@node4 ~]# yum -y install bzip2
[root@node4 ~]# tar xf nextcloud-latest.tar.bz2 -C /var/www/html/
[root@node4 ~]# chown apache.apache -R /var/www/html/
需要修改为运行web服务器的用户owner,group,否则后面写入会出现权限问题4, 通过浏览器访问 http:192.168.120.104/nextcloud ,进行配置
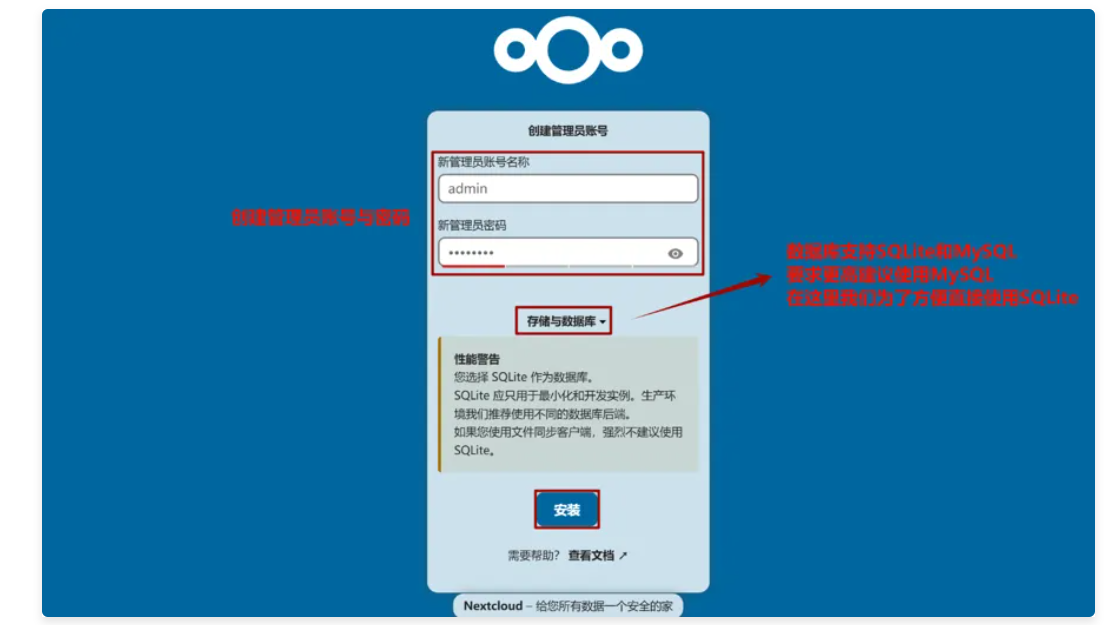


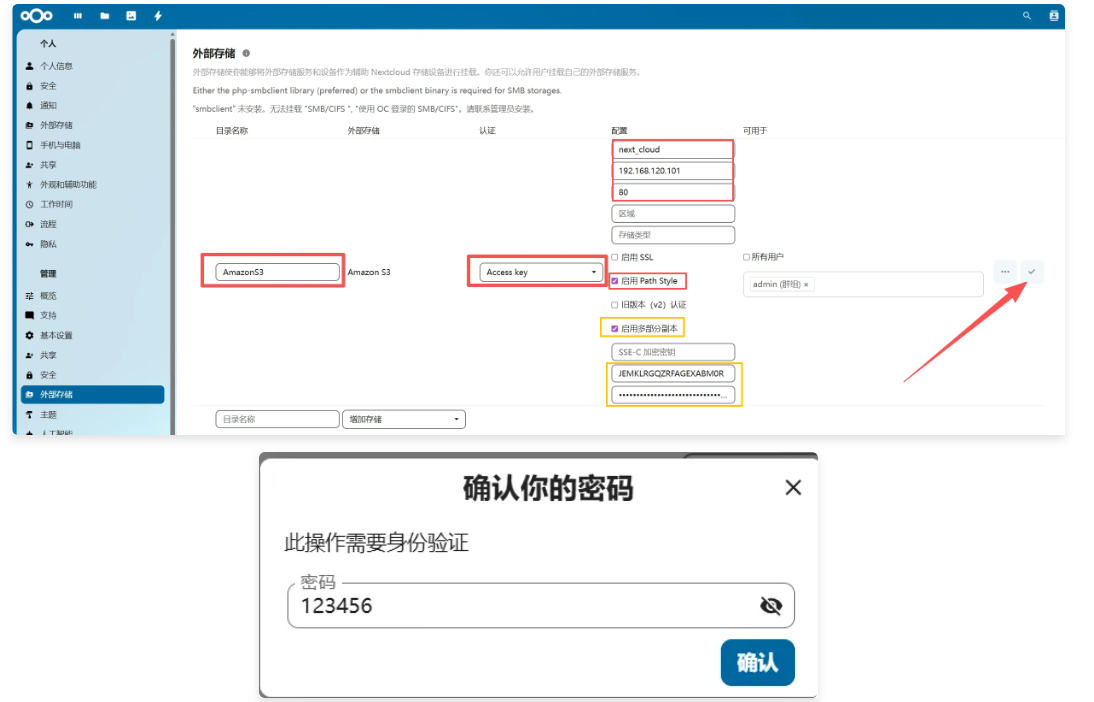
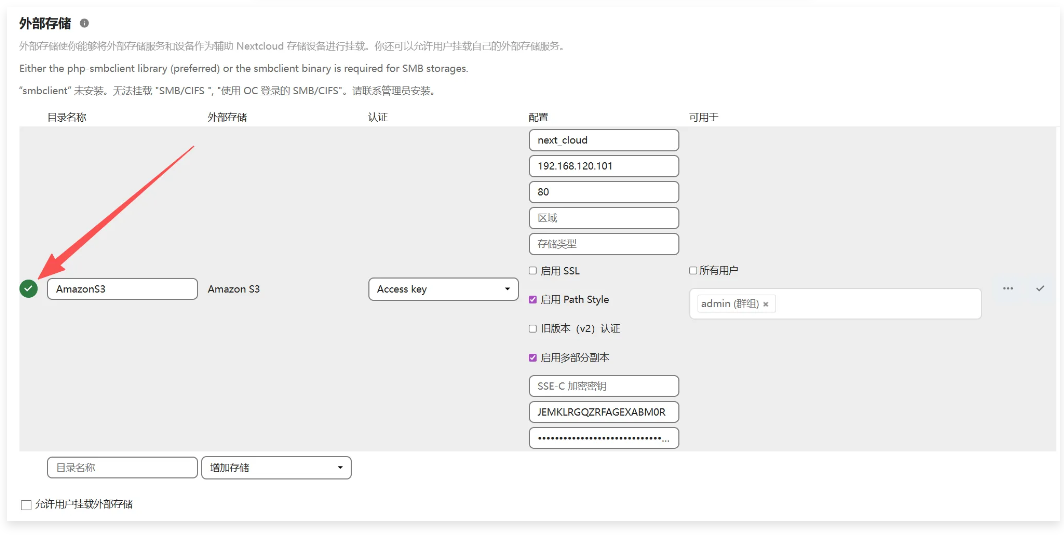
文件上传下载测试
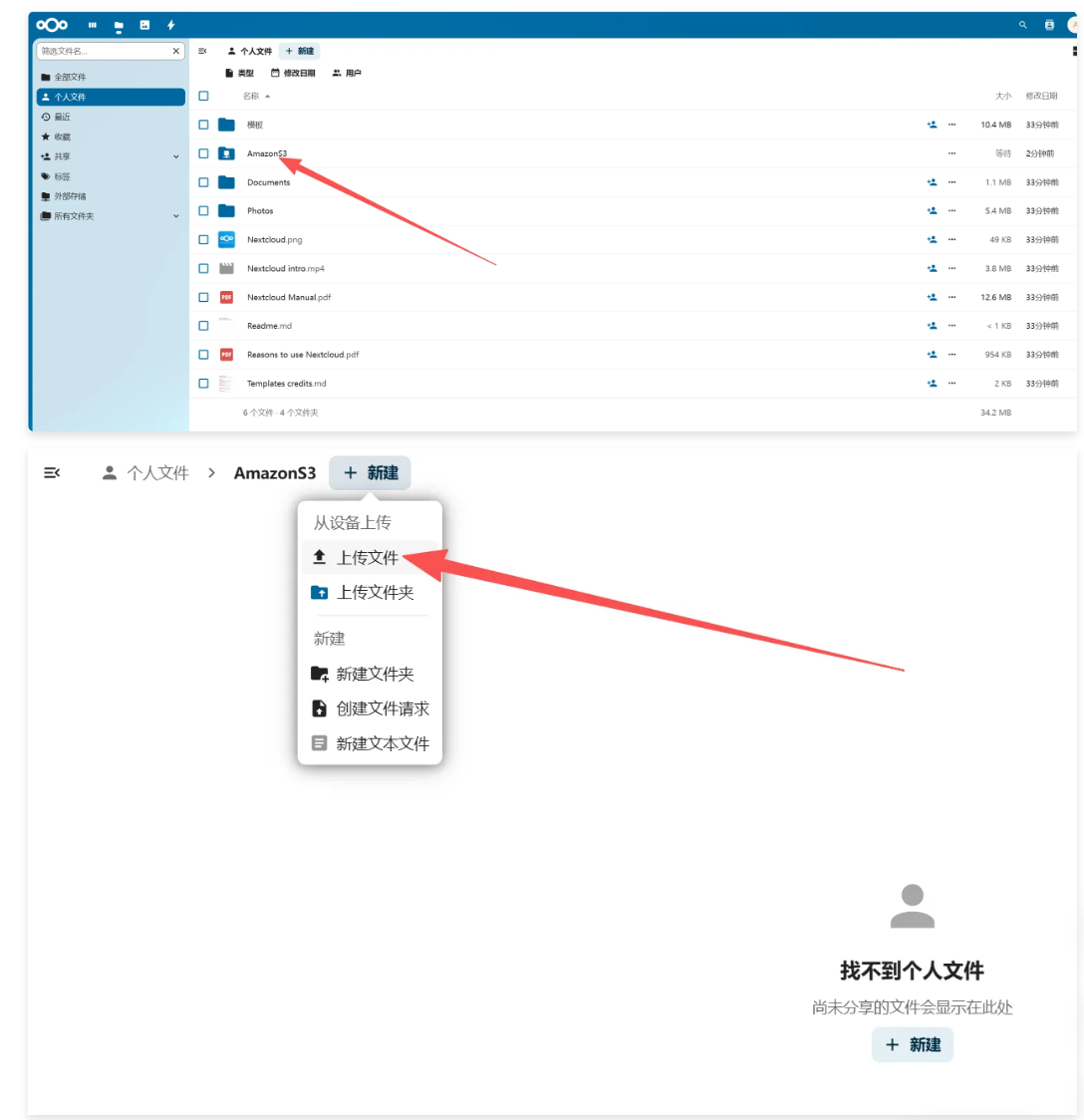
[root@node4 ~]# s3cmd put /etc/fstab s3://next_cloud
upload: '/etc/fstab' -> 's3://next_cloud/fstab' [1 of 1]
579 of 579 100% in 0s 51.34 KB/s done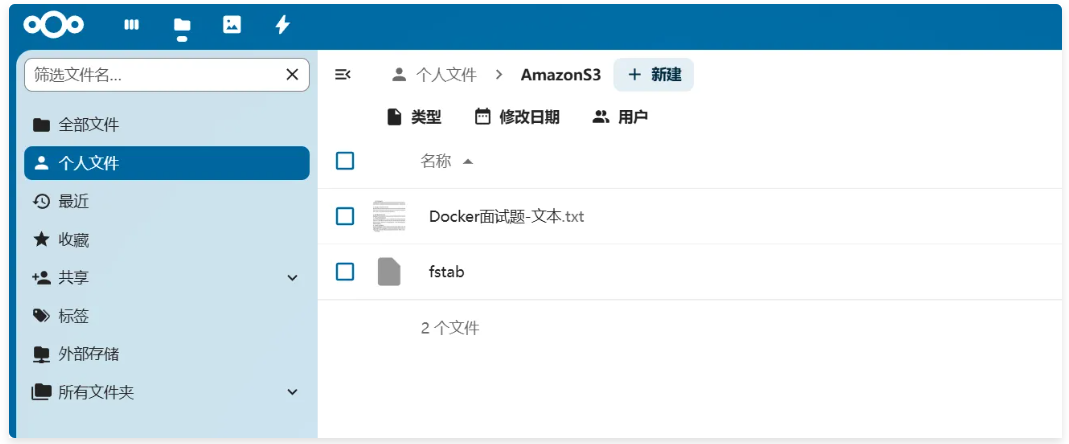
[root@node4 ~]# s3cmd ls s3://next_cloud
2025-12-11 08:34 26151 s3://next_cloud/Docker面试题-文本.txt
2025-12-11 08:34 579 s3://next_cloud/fstab