安装配置 ELK 集群实现海量日志集中分析处理
1. ELK 简介
1.1 ELK 和各组件的概述
ELK 是三个开源软件的缩写,分别为:Elasticsearch 、Logstash 以及 Kibana , 它们都是开源软件。不过现在还新增了一个 Beats,它是一个轻量级的日志收集处理工具(Agent),Beats 占用资源少,适合于在各个服务器上搜集日志后传输给 Logstash,官方也推荐此工具,目前由于原本的 ELK Stack 成员中加入了 Beats 工具所以已改名为 Elastic Stack。
三个软件的作用如下:
1、Elasticsearch 是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能,他是基于 lucene的搜索服务器,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful 风格接口,多数据源,自动搜索负载等。
Lucene 是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文不德文两种西方诧言)。
Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
2、Logstash 主要是用来日志的搜集、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s 架构,client(rsyslog,apache,nginx)端安装在需要收集日志的主机上,server Logstash 端负责将收到的各节点日志迚行过滤、修改等操作在一并发往 elasticsearch 上去。
3、Kibana 也是一个开源和免费的工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮忙汇总、分析和搜索重要数据日志。
4、Beats 在这里是一个轻量级日志采集器,其实 Beats 家族有 6 个成员,早期的 ELK 架构中使用Logstash 收集、解析日志,但是 Logstash 对内存、cpu、io 等资源消耗比较高。相比 Logstash,Beats所占系统的 CPU 和内存几乎可以忽略不计。
1.2 ELK 使用场景
一般我们需要迚行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大也就是日志量多而复杂的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎举办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
大型系统通常都是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:
收集-能够采集多种来源的日志数据
传输-能够稳定的把日志数据传输到中央系统
存储-如何存储日志数据
分析-可以支持 UI 分析
警告-能够提供错误报告,监控机制
而 ELK 则提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。是目前主流的一种日志系统。
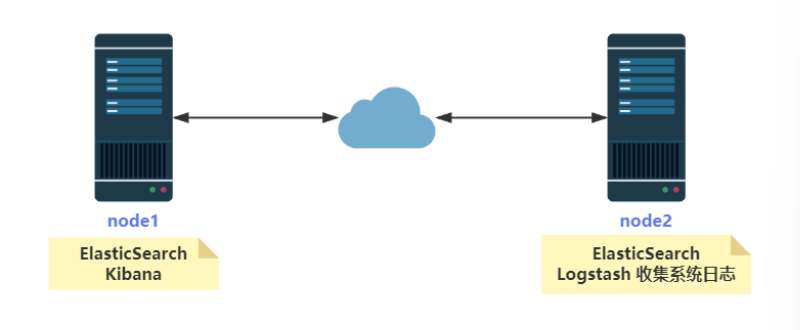
实验拓扑图:
本章使用设备清单及配置:
注:两台机器都需要,配置为 4 核 CPU,6G 以上内存 。本章节启动的服务较多,尽量把配置给的高一些!
2. 安装配置 elasticsearch 集群
2.1 在 node1 上安装 JDK 环境
上传 jdk1.8 到 node1 上
[root@node1 ~]# rpm -ivh jdk-8u201-linux-x64.rpm
[root@node1 ~]# java -version
java version "1.8.0_201"
#关闭防火墙和 selinux
[root@node1 ~]# systemctl stop firewalld && systemctl disable firewalld
[root@node1 ~]# setenforce 0
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.120.191 node1
192.168.120.192 node22.2 在 node1 安装 elasticsearch
上传 elasticsearch-6.6.1.rpm 到 node1 上
[root@node1 ~]# rpm -ivh elasticsearch-7.8.1-x86_64.rpm
#或者在线安装:
[root@node1 ~]# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
[root@node1 ~]# vim /etc/yum.repos.d/elastic.repo # 增加以下内容
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
[root@node1 ~]# yum install -y elasticsearch
#创建日志目录和索引文件目录
[root@node1 ~]# mkdir -p /data/elasticsearch/log /data/elasticsearch/data
[root@node1 ~]# chown -R elasticsearch:elasticsearch /data/elasticsearch/
[root@node1 ~]# chown -R elasticsearch:elasticsearch /etc/elasticsearch/2.3 node1上配置 JVM 内存和 elasticsearch 集群参数
1. 配置 JVM 可用的内存
[root@node1 ~]# ls /etc/elasticsearch
elasticsearch.yml jvm.options log4j2.properties
[root@node1 ~]# vim /etc/elasticsearch/jvm.options
改
22 -Xms1g # JVM 初始分配的堆内存
23 -Xmx1g # JVM 最大可以使用的内存
为:
-Xms2g
-Xmx2g
2. 配置集群参数
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml # 增加戒更改以下内容
改:33 path.data: /var/lib/elasticsearch
为: path.data: /data/elasticsearch/data #数据和索引存放路径
改:37 path.logs: /var/log/elasticsearch
为:path.logs: /data/elasticsearch/log #日志存放路径
最下面一行添加以下内容
cluster.name: node
node.name: node1
node.master: true
node.data: true
network.host: 192.168.120.191
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.120.191", "192.168.120.192"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
cluster.initial_master_nodes: node1
------------------------------
配置说明:
cluster.name: node # 集群中的名称
node.name: node1 # 该节点名称
node.master: true # 该节点为主节点
node.data: true # 表示这是数据节点
network.host: 192.168.120.191 # 监听全部 ip,在实际环境中应设置为一个安全的
http.port: 9200 # elasticsearch 服务的端口号
discovery.zen.ping.unicast.hosts: ["192.168.120.191", "192.168.120.192"] # 集群单播发现主机,这个配置一般写主节点和备用主节点的 IP
discovery.zen.minimum_master_nodes: 2 #对集群的稳定性至关重要,防止脑裂的出现。
扩展:防止脑裂的出现
如果网络的故障导致一个集群被划分成两片,每片都有多个 node,以及一个 master。因为 master是维护集群状态,以及 shard 的分配。如果出现了两个 master,可能导致数据破损。
discovery.zen.minimum_master_nodes 的作用是只有足够的 master 候选节点时,才可以选举出一个 master。该参数必须设置为集群中 master 候选节点的 quorum 数量。2.4 在 node2 上安装 JDK 环境
1. 上传 jdk1.8 到 node2 上
[root@node2 ~]# rpm -ivh jdk-8u201-linux-x64.rpm
[root@node2 ~]# java -version
java version "1.8.0_201"
#关闭防火墙和 selinux
[root@node2 ~]# systemctl stop firewalld && systemctl disable firewalld
[root@node2 ~]# setenforce 0
#修改/etc/hosts 文件
[root@node2 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.120.191 node1
192.168.120.192 node22.5 node2 上配置 JVM 内存和 elasticsearch 集群参数
#上传 elasticsearch-6.6.1.rpm 到 node2 上
[root@node2 ~]# rpm -ivh elasticsearch-7.8.1-x86_64.rpm
#创建日志目录和索引文件目录
[root@node2 ~]# mkdir -p /data/elasticsearch/log /data/elasticsearch/data
[root@node2 ~]# chown -R elasticsearch:elasticsearch /data/elasticsearch/
[root@node2 ~]# chown -R elasticsearch:elasticsearch /etc/elasticsearch/
#配置 JVM 可用的内存
[root@node2 ~]# vim /etc/elasticsearch/jvm.options
改
22 -Xms1g # JVM 初始分配的堆内存
23 -Xmx1g # JVM 最大可以使用的内存
为:
22 -Xms2g
23 -Xmx2g
# 增加戒更改以下内容
[root@node2 ~]# vim /etc/elasticsearch/elasticsearch.yml
改:33 path.data: /var/lib/elasticsearch
为: path.data: /data/elasticsearch/data #数据和索引存放路径
改:37 path.logs: /var/log/elasticsearch
为:path.logs: /data/elasticsearch/log #日志存放路径
---------------------------------------------------
最下面一行添加以下内容
cluster.name: node
node.name: node2
node.master: true
node.data: true
network.host: 192.168.120.192
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.120.191", "192.168.120.192"]
discovery.zen.minimum_master_nodes: 2
gateway.recover_after_nodes: 2
cluster.initial_master_nodes: node1
注:
node.name: node2 # 该节点名称不能和 node1 重复
network.host: 192.168.120.192 # 监听 ip,在实际环境中应设置为一个安全的
node.data: true # 表示这是一个数据节点2.6 启动 Elasticsearch 集群
#先启动 node1,再启动 node2
[root@node1 ~]# systemctl start elasticsearch.service && systemctl enable elasticsearch.service && systemctl status elasticsearch
#上面启动服务后,需要等 10 秒左右(因机器配置,可能还会长一些),才可以看到监听的这两个端口号
[root@node1 ~]# netstat -lntp | grep java
tcp6 0 0 192.168.120.191:9200 :::* LISTEN 2824/java
tcp6 0 0 192.168.120.191:9300 :::* LISTEN 2824/java
[root@node2 ~]# systemctl start elasticsearch.service && systemctl enable elasticsearch.service && systemctl status elasticsearch
[root@node2 ~]# netstat -lntp | grep java
tcp6 0 0 192.168.120.192:9200 :::* LISTEN 2161/java
tcp6 0 0 192.168.120.192:9300 :::* LISTEN 2161/java2.7 查看 elasticsearch 集群情况
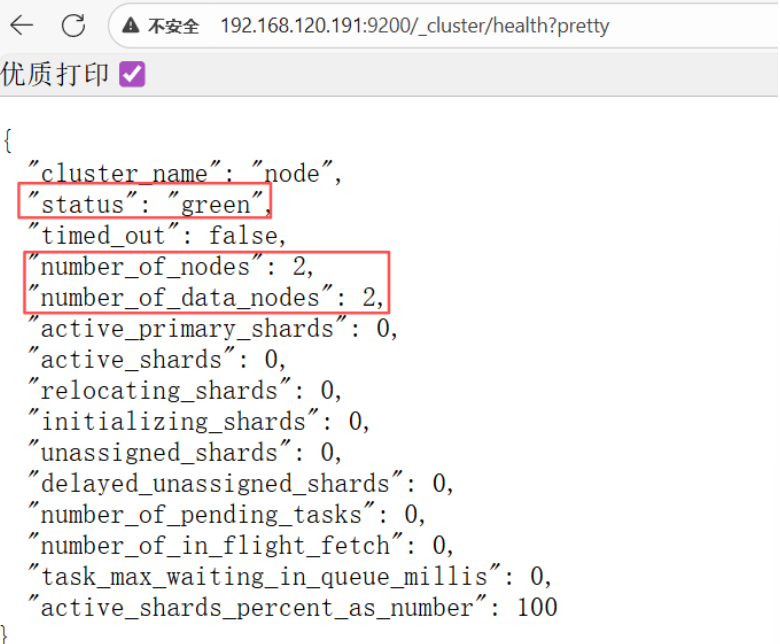
浏览器查看集群健康状态:http://192.168.120.191:9200/_cluster/health?pretty
查看单台机器:http://192.168.120.191:9200/
2.8 使用 curl 管理 elasticsearch 集群
#创建索引
[root@node1 ~]# curl -XPUT 'http://192.168.120.191:9200/test/'
#下面插入数据
[root@node1 ~]#curl -H 'Content-Type: application/json' -XPUT 'http://192.168.120.191:9200/test/student/1' -d '{"name":"dir","age":"30","info":"I love you"}'
#参数说明:-H/--header <line>自定丿头信息传递给服务器也可以直接创建索引以及数据
#也可以直接创建索引以及数据
[root@node1 ~]#curl -H 'Content-Type: application/json' -XPUT 'http://192.168.120.191:9200/demo/student/1' -d '{"name":"dir","age":"30","info":"I love you"}'
#查看索引内容
#语法:ip:port/index/type/id -d {text}
[root@node1 ~]# curl -X GET http://192.168.120.191:9200/test/student/1?pretty
{
"_index" : "test",
"_type" : "student",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "dir",
"age" : "30",
"info" : "I love you"
}
}
#curl 命令操作 elasticsearch
#cat 命令
[root@node1 ~]#curl -X GET 192.168.120.191:9200/_cat
#查看索引信息
[root@node1 ~]# curl -X GET '192.168.120.191:9200/_cat/indices?v'
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open test b-fXxwfHRUC6oFRIlxSLRA 1 1 0 0 4.8kb 208b
#cluster 命令
#查看集群状态
[root@node1 ~]# curl '192.168.120.191:9200/_cluster/health?pretty'
{
"cluster_name" : "node",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 2,
"number_of_data_nodes" : 2,
"active_primary_shards" : 1,
"active_shards" : 2,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
#查看集群节点状态
[root@node1 ~]# curl -X GET 192.168.120.191:9200/_cat/nodes?pretty
192.168.120.191 51 97 0 0.00 0.01 0.05 dilmrt * node1 #这是 master
192.168.120.192 50 97 0 0.07 0.03 0.05 dilmrt - node2
#总结:现在显示出来的都是一堆字符串,我们希望这些信息能以图形化的方式显示出来,那就需要安装 kibana 来为我们展示这些数据了。3. 在 node2 上安装 Logstash 收集本机系统日志
3.1 安装 logstash 收集日志
node2 作为 ELK 集群中需要分析日志的机器。后期需要收集哪台机器上的日志,就把 logstash安装到那台服务器上
在 192.168.120.192 上安装 logstash,但是要注意的是目前 logstash 不支持 JDK1.9
上传 logstash 到 Linux 系统上
[root@node2 ~]# rpm -ivh logstash-7.8.1.rpm
Successfully created system startup script for Logstash
#在线安装方法:如果前面配置了 elk 的 yum 源,则所有的软件包都可以直接通过 yum 迚行安装,但是 yum 源可能会比较慢。
[root@node2 ~]# yum install logstash 或 wget https://artifacts.elastic.co/downloads/logstash/logstash-7.8.1.rpm3.2 配置 logstash 收集 node2 的系统日志
1、指定所有类型的日志都上传到 192.168.120.192:10514 端口
[root@node2 ~]# vim /etc/rsyslog.conf #在文件最后,插入
*.* @@192.168.120.192:10514
#重启一下 rsyslog 服务是配置生效
[root@node2 ~]# systemctl restart rsyslog配置 logstash 收集 syslog 日志,并把收集到的日志传输到 es 服务器中
[root@node2 ~]# cat /etc/logstash/conf.d/syslog.conf
input { # 定义日志源
syslog {
type => "system-syslog" # 定义类型
port => 10514 # 定义接收系统日志的监听端口
}
}
output {
elasticsearch {
hosts => ["192.168.120.191:9200"] # 定义 es 服务器的 ip
index => "system-syslog-%{+YYYY.MM}" # 定义索引 kibana 是通过索引检索数据的
}
}配置环境变量,如果丌配置的话执行 logstash 命令则需使用绝对路径
[root@node2 ~]# vim /etc/profile.d/logstash.sh #创建这个文件,并插入以下内容
LS=/usr/share/logstash/
PATH=$LS/bin:$PATH
export LS PATH
[root@node2 ~]# source /etc/profile检查配置文件
[root@node2 ~]# logstash --path.settings /etc/logstash/ -f /etc/logstash/conf.d/syslog.conf --config.test_and_exit
配置文件没有问题 命令说明: --path.settings 用于指定 logstash 的配置文件所在的目录 -f 指定需要被检测的配置文件的路径 --config.test_and_exit 指定检测完之后就退出,不然就会直接启动了
修改一下配置文件,配置一下监听的 ip:
logstash 服务默认监听 ip 是 127.0.0.1 这个本地 ip,本地 ip 无法进程通信,所以需要修改
[root@node2 ~]# vim /etc/logstash/logstash.yml
改
223 # http.host: "127.0.0.1"
为
http.host: "192.168.120.192"给相关目录权限
[root@node2 ~]# chown -R logstash /var/lib/logstash/ /var/log/logstash/重启 logstash
[root@node2 ~]# systemctl restart logstash && systemctl enable logstash && systemctl status logstash
[root@node2 ~]# netstat -lntp | grep 9600 #等 30 秒后,可以看到端口开启
tcp6 0 0 192.168.120.192:9600 :::* LISTEN 18151/java
[root@node2 ~]# netstat -lntp | grep 10514
tcp6 0 0 :::10514 :::* LISTEN 18151/java产生一些系统日志,这样 logstash 才可以采集到日志放到 es 服务器上,然后才能看到日志索引和数据:
[root@node1 ~]# ssh 192.168.120.192 #登录系统会产生日志
[root@node2 ~]# tail -f /var/log/secure #查看日志完成了 logstash 服务器的搭建之后执行以下命令可以获取索引信息:
http://192.168.120.191:9200/_cat/indices?v

如上,可以看到,在 logstash 配置文件中定丿的 system-syslog 索引成功获取到了,证明配置没问题,logstash 不 es 通信正常
获取指定索引详细信息:
[root@node1 ~]# curl -XGET '192.168.120.191:9200/system-syslog-2025.12?pretty'
# 注:system-syslog-2025.12 为索引名称,是根据你系统的时间,生成的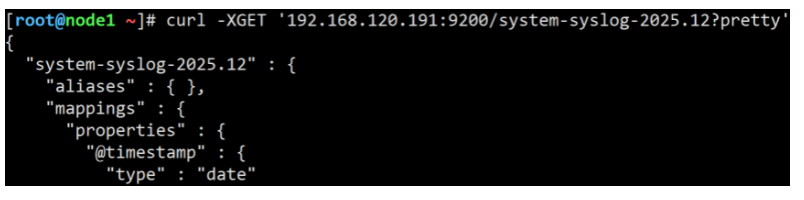
如果日后需要删除索引的话,使用以下命令可以删除指定索引:
[root@node1 ~]# curl -XDELETE '192.168.120.191:9200/system-syslog-2025.11' #先不删除。后期要使用这个索引3.3 配置 logstash 收集挃定日志文件
前面收集日志是通过 logstash 接受 rsyslog 服务的日志然后 logstash 将日志发送给 es 服务器,这种收到的日志太多,很多没有用。 es 服务器也可以文件的形式来读取日志,这种更加精确。
[root@node2 ~]# vim /etc/logstash/conf.d/messages.conf
input { # 定义日志源
file {
path => "/var/log/messages" #定义收集的日志源文件
type => "system" #定义日志类型
start_position => "beginning" #检查时间戳
sincedb_path => "/tmp/mysincedbfile" # sincedb_path 指定 sincedb 文件的路径
}
}
output {
elasticsearch {
hosts => ["192.168.120.191:9200"] # 定义 es 服务器的 ip
index => "system-messages-%{+YYYY.MM}" # 定义索引 kibana 是通过索引检索数据的
}
}注:start_position 是 logstash 默认是从结束位置开始读取文件数据,也就是说 logstash 进程会以类似 tail -f 的形式运行。如果你是要导入原有数据,把这个设定改成“beginning”,logstash 进程就按时间戳记录的地方开始读取,如果没有时间戳则从头开始读取,有点类似 cat,但是读到最后一行不会终止,而是继续变成 tail -f。
sincedb_path 指定 sincedb 文件的路径。sincedb 保存每个日志文件已经被读取到的位置,如果Logstash 重启,对于同一个文件,会继续从上次记录的位置开始读取。如果想重新从头读取文件,需要删除 sincedb 文件。
扩展:sincedb 如果想每次都从文件头开始读取文件怎么办?sincedb_path 指向/dev/null 即可,这样 logstash 每次读取时间戳位置都是空,就会从文件开头进行去读取日志。
添加权限
[root@node2 ~]# chmod 755 -R /var/log/*
[root@node2 ~]# systemctl restart logstash查看索引信息: http://192.168.120.191:9200/_cat/indices?v

4. 安装并汉化 kibana-使用 kibana 以图形界面显示系统日志
4.1 安装 kibana 并配置汉化
上传 kibana-7.8.1-x86_64.rpm 安装包到 node1 服务器
[root@node1 ~]# rpm -ivh kibana-7.8.1-x86_64.rpm
#在线安装方法:(需配置 yum 源,配 置方法和安装 elasticsearch 的源一致。)
[root@node1 ~]# yum install -y kibana安装完成后,对 kibana 进行配置:
[root@node1 ~]# vim /etc/kibana/kibana.yml
改:2 #server.port: 5601
为:server.port: 5601 # 配置 kibana 的端口
改:7 #server.host: "localhost"
为:server.host: "192.168.120.191" # 配置监听 ip
改:28 # elasticsearch.hosts: ["http://localhost:9200"]
为:elasticsearch.hosts: ["http://192.168.120.191:9200"] # 配置 es 服务器的 ip,如果是集群则配置该集群中主节点的 ip
改:97 #logging.dest: stdout
为:logging.dest: /var/log/kibana.log # 配置 kibana 的日志文件路径,不然默认在/var/log/messages 中记录日志
#配置汉化,i18n.locale: 后必须要有空格,否则配置不生效
改:115 #i18n.locale: "en"
为:i18n.locale: "zh-CN"创建日志文件:
[root@node1 ~]# touch /var/log/kibana.log && chown kibana:kibana /var/log/kibana.log
#启动 kibana 服务,并检查进程和监听端口:
[root@node1 ~]# systemctl restart kibana && systemctl enable kibana
[root@node1 ~]# ps aux | grep kibana
kibana 19980 60.7 2.2 625904 91924 ? Dsl 19:23 0:04 /usr/share/kibana/bin/../node/bin/node /usr/share/kibana/bin/../src/cli
root 20013 0.0 0.0 112824 980 pts/0 S+ 19:23 0:00 grep --color=auto kibana
#注:由于 kibana 是使用 node.js 开发的,所以进程名称为 node
[root@node1 ~]# netstat -lntp | grep 5601 #等 20 秒才可以看到进程
tcp 0 0 192.168.120.191:5601 0.0.0.0:* LISTEN 19980/node 访问:http://192.168.120.191:5601
web 界面小技巧
这样界面会更加便于我仧操作,但是大家在仪表盘中查看图表时可以将导航隐藏。官方特意把导航栏做的可以隐藏,这点新版本体验非常好。
4.2 配置 kibana 显示系统日志
浏览器访问 192.168.120.191:5601,到 kibana 页面上配置索引
我们可以使用通配符,迚行批量匹配, 也可以直接输入一个索引名称
创建索引
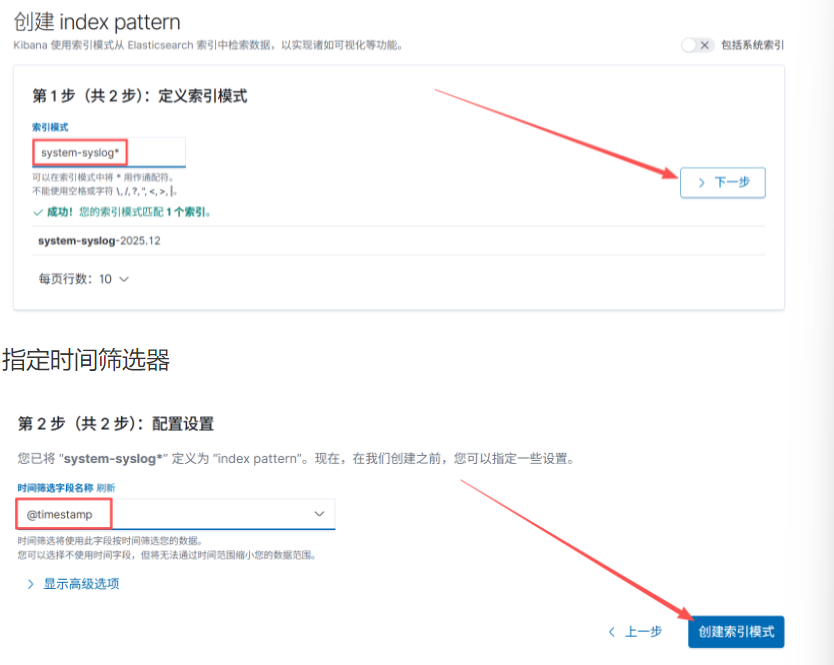
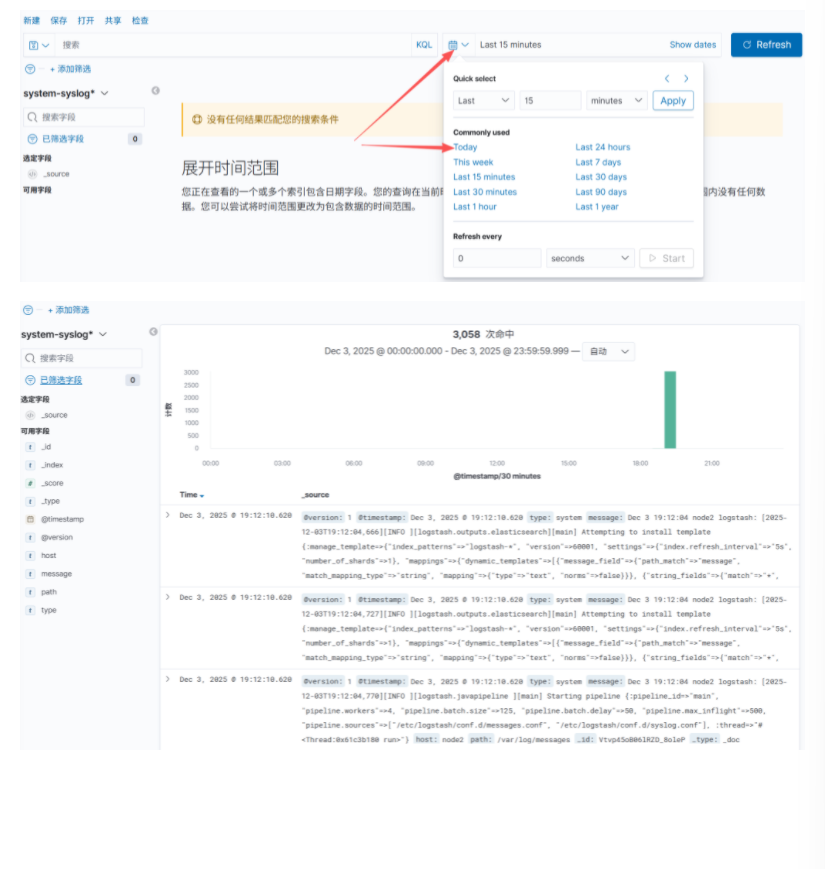
配置成功后点击 “Discover” 下拉选择 system-syslog 日志
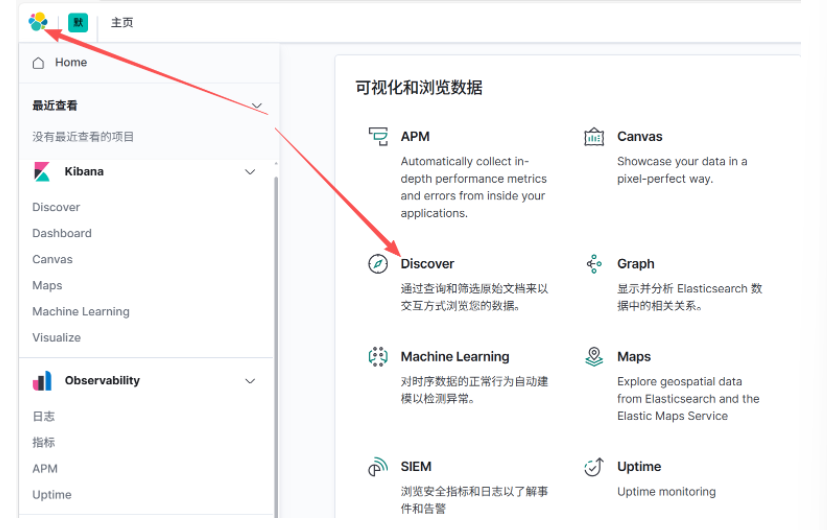
默认是 15 分钟,如果我们刚做完,是没有数据的。右边日期栏设置时间为:today,这样就有数据了。也自定义选择时间范围。